

 By Rick Ryan, Envisn, Inc.
By Rick Ryan, Envisn, Inc.
One of the ongoing major tasks in any Cognos environment is the need to manage change. Changes to ERP systems, databases, data sources, etc. occur on a regular basis. This requires changes to FM Models, packages, reports, queries, etc. Ideally you get notified of these well in advance of the actual change so they can be addressed in a planful way. But sometimes the change has already occurred and you need to fix things.
Beyond knowledge a forehand though, there are other things you need in order to make object changes quickly, accurately and easily. You also need:
- Precise detail: Finding these objects with exactly these attributes.
- Complete capture: The knowledge that you can capture all objects in the Content Store with the defined attributes. What good is it if you miss a lot of objects?
- Timing: Exactly when these changes need to be made and available in production.
- Tools: The right tool for making accurate changes with minimal steps involved.
- Testing or validation: Insuring that the changes to the objects were successful.
If you’ve tried to manage changes like this manually you already know how boring, tedious and inaccurate this can be. And the larger and more complex your environment is the more impossible this can be to get it right. But all of these things are possible if you have the Cognos metadata at the right level of granularity. This makes it possible to make changes or identify data usage on things like:
- Model Reference –To make model changes to selected reporting objects.
- Package Dependency – Change the package dependency on selected objects.
- Specification Change – Change specifications on selected objects (Example: We want to change the logo used on our reports.)
- Database Dependency – Identify all objects using certain databases, tables or columns.
If you have read the early blogs in this Cognos metadata series you already understand that the secret to doing this revolves around two things; first, you have to atomize the metadata in Cognos and do it in a manner that key attributes are retained. And second, you have to persist the metadata (store it) so it can be available for multiple different uses any time you need it. Practically speaking, you cannot do this by going directly against the Content Store to query it for metadata when needed.
Database Dependency
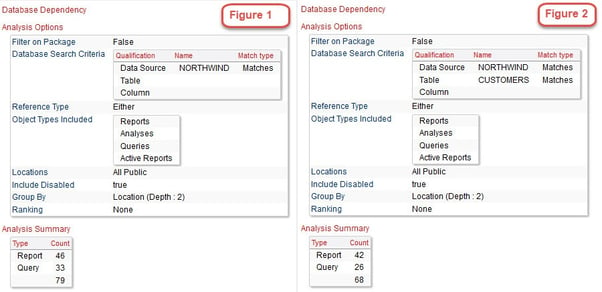
With this metadata we can identify virtually any dependency not only between objects, but for any particular object within the Content Store. For example, if we wanted to know which objects are dependent upon the Northwind database currently in use we can run an analysis that shows that.
In Figure 1 we see that there are a total of 79 objects that are using Northwind database. In Figure 2 we’ve further narrowed the search to the Customers table only within the Northwind database and this shows 68 objects using that table.
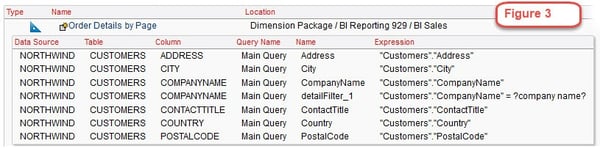
But we need to know more here. Specifically exactly which of those 68 objects are using columns or fields of the Northwind database and their location. In Figure 3 we can see one of these 68 reports, the report Order Details by Page and its folder location along with all of the columns used in the report from Northwind database.
As a next step we could, if needed, replace key data fields if necessary on a single report or multiple reports at the same time and be assured that we have captured all objects that have met our search criteria.
Changing Package Dependency
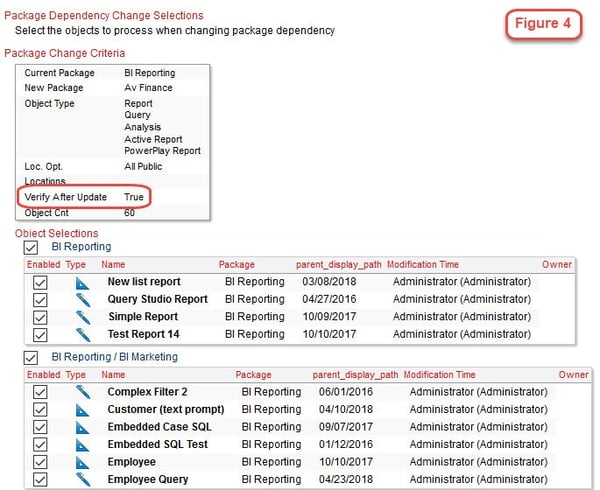
With the metadata strategy that we’ve adopted we have the ability to make mass changes and updates. In this next example, Figure 4, we are going to identify the objects currently dependent on an existing package and change them over to a new package. Note that we can make this change for 60 of the objects identified, or do it selectively if we wish. Another advantage is that we can verify that these objects will function correctly after the change takes place. This insures that all of the objects will function correctly following the package change. And we have a full log history of all changes with details that have taken place.
Impact Analysis - Beyond Data Dependency
There are multiple types of impact analyses that Cognos administrators face daily that go beyond data dependencies. Examples include things like triggers, job steps, report descriptions, etc. The list is virtually limitless and can include all the things you need to manage your Cognos environment; even those you may need to use only once or twice a year. Examples include:
- All Job Step Details
- Cognos Objects Sending Attachments by Location
- Cognos Objects Sending Attachments by Package
- All Cognos Schedule Detail
- All Cognos Report Descriptions
- All Objects With a Defined Trigger
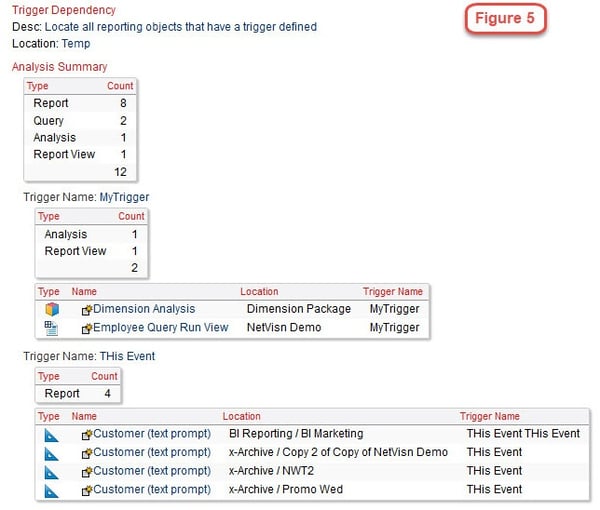
In Figure 5 we see a partial listing of all triggers in the Cognos environment. This information is very useful when you need to identify objects with triggers in an effort to standardize naming conventions.
It’s All There
Impact analysis is mostly often associated with data dependencies but it is best defined more broadly in Cognos as change analysis. Why? Because the major constant in any Cognos environment is change and without the tools to manage change it can be very hard to stay on top of things. Being able to capture all of the metadata in Cognos for use whenever you need it is not only possible but essential. You really can have it all!
© 2018 Envisn, Inc. – All rights reserved. Cognos Metadata Universe: Unmasking Security


